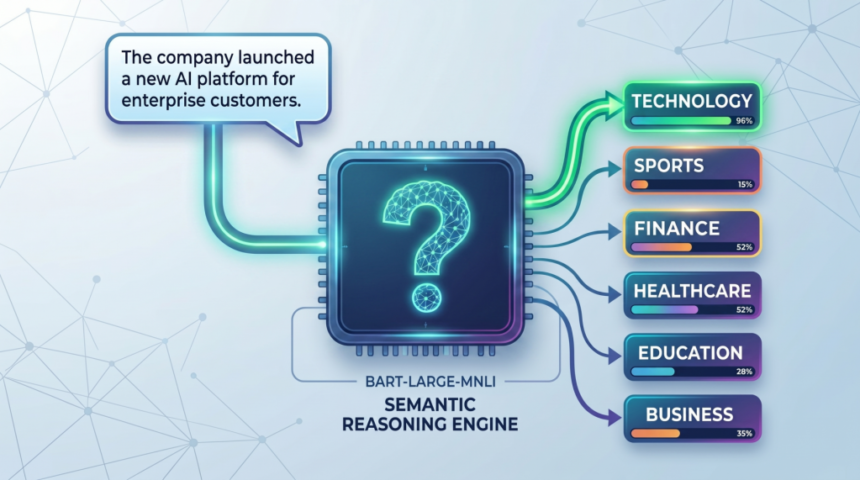
Introduction to Zero-Shot Text Classification
Zero-shot text classification is a revolutionary approach in natural language processing that enables models to categorize text into predefined categories without requiring any prior training data. This innovative technique has garnered significant attention in recent years due to its potential to streamline text analysis tasks and improve the efficiency of various applications, including sentiment analysis, topic modeling, and information retrieval.
How Zero-Shot Text Classification Works
The core idea behind zero-shot text classification is to leverage a pretrained transformer model, which has been trained on a massive corpus of text data, to classify new, unseen text into predefined categories. This is achieved by using the model’s ability to generate text representations that capture the semantic meaning of the input text. The model can then compare these representations to a set of predefined category representations to determine the most likely category for the input text.
To get started with zero-shot text classification, you’ll need to select a suitable pretrained transformer model, such as BERT or RoBERTa, and fine-tune it on your specific task. You’ll also need to prepare your dataset, which should include a set of text samples and their corresponding category labels.
Benefits and Applications
- Improved accuracy: Zero-shot text classification can achieve high accuracy even with limited training data.
- Increased efficiency: This approach can significantly reduce the time and effort required for text analysis tasks.
- Flexibility: Zero-shot text classification can be applied to a wide range of applications, including sentiment analysis, topic modeling, and information retrieval.











